Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
På den här sidan beskrivs hur du utvecklar kod i Databricks-notebook-filer, inklusive kodformatering, automatisk komplettering, blandning av språk och magiska kommandon.
Mer information om avancerade funktioner som är tillgängliga i redigeraren, till exempel automatiskt slutförande, variabelval, stöd för flera markörer och jämförelse sida vid sida, finns i Navigera i Databricks notebook och filredigeraren.
När du använder notebook-filen eller filredigeraren är Genie Code tillgängligt för att hjälpa dig att generera, förklara och felsöka kod. Mer information finns i Använda Genie Code .
Databricks-notebook-filer innehåller också ett inbyggt interaktivt felsökningsprogram för Python notebook-filer. Se Felsöka notebook-filer.
Viktigt!
Anteckningsboken måste vara ansluten till en aktiv compute-session för kodhjälpsfunktioner, inklusive automatisk komplettering, Python kodformatering och felsökningsprogrammet.
Modularisera koden
Med Databricks Runtime 11.3 LTS och senare kan du skapa och hantera källkodsfiler i Azure Databricks arbetsyta och sedan importera filerna till dina notebook-filer efter behov.
Mer information om hur du arbetar med källkodsfiler finns i Share code between Databricks notebooks and Work with Python and R modules.
Formatera kodceller
Azure Databricks innehåller verktyg som gör att du kan formatera Python och SQL-kod i notebook-celler. De här verktygen minskar arbetet med att hålla koden formaterad och bidra till att tillämpa samma kodningsstandarder i dina notebook-filer.
Python svart formateringsbibliotek
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Azure Databricks stöder Python kodformatering med hjälp av black i notebook-filen. Notebook-filen måste vara ansluten till ett kluster med paketen black och tokenize-rt Python installerat.
På Databricks Runtime 11.3 LTS och senare förinstallerar Azure Databricks black och tokenize-rt. Du kan använda formateringen direkt utan att behöva installera dessa bibliotek.
På Databricks Runtime 10.4 LTS och tidigare måste du installera black==22.3.0 och tokenize-rt==4.2.1 från PyPI i notebooken eller klustret för att använda Python-formatteraren. Du kan köra följande kommando i anteckningsboken:
%pip install black==22.3.0 tokenize-rt==4.2.1
eller installera biblioteket i klustret.
Mer information om hur du installerar bibliotek finns i Python miljöhantering.
För filer och notebook-filer i Databricks Git-mappar kan du konfigurera Python formaterare baserat på filen pyproject.toml. Om du vill använda den här funktionen skapar du en pyproject.toml fil i Git-mappens rotkatalog och konfigurerar den enligt formatet Svart konfiguration. Redigera avsnittet [tool.black] i filen. Konfigurationen tillämpas när du formaterar alla filer och anteckningsböcker i git-mappen.
Formatering av Python- och SQL-celler
Du måste ha redigeringsbehörighet i anteckningsbok för att formatera kod.
Azure Databricks använder en anpassad SQL-formaterare för att formatera SQL och black kodformaterare för Python.
Du kan utlösa formateraren på följande sätt:
Formatera en enskild cell
- Kortkommando: Tryck på Cmd+Skift+F.
- Snabbmeny för kommando:
- Formatera SQL-cell: Välj Formatera SQL i kommandokontextens listruta för en SQL-cell. Det här menyalternativet är endast synligt i SQL Notebook-celler eller i de med språkmagi
%sql. - Formatera Python cell: Välj Format Python i listrutan kommandokontext i en Python cell. Det här menyalternativet visas bara i Python notebook-celler eller i celler med
%pythonlanguage magic.
- Formatera SQL-cell: Välj Formatera SQL i kommandokontextens listruta för en SQL-cell. Det här menyalternativet är endast synligt i SQL Notebook-celler eller i de med språkmagi
- Menyn Notebook Edit: Välj en Python- eller SQL-cell och välj sedan Redigera > Formatera celler .
Formatera flera celler
Markera flera celler och välj sedan Redigera > Formatera cell(er). Om du markerar celler med fler än ett språk formateras endast SQL- och Python celler. Detta inkluderar de som använder
%sqloch%python.Formatera alla Python- och SQL-celler i notebook-filen
Välj Redigera > anteckningsbokens format. Om notebook-filen innehåller mer än ett språk formateras endast SQL- och Python celler. Detta inkluderar de som använder
%sqloch%python.
Information om hur dina SQL-frågor formateras finns i SQL-instruktioner i anpassat format.
Begränsningar i kodformatering
- Black tillämpar PEP 8-standard för indrag med fyra mellanslag. Indrag kan inte konfigureras.
- Formatering av inbäddade Python strängar i en SQL UDF stöds inte. På samma sätt stöds inte formatering av SQL-strängar i en Python UDF.
Kodspråk i notebook-filer
Ange standardspråk
Standardspråket för notebook-filen visas under anteckningsbokens namn.

Om du vill ändra standardspråket klickar du på språkknappen och väljer det nya språket på den nedrullningsbara menyn. För att säkerställa att befintliga kommandon fortsätter att fungera prefixas kommandon för det tidigare standardspråket automatiskt med ett språkmagikommando.
Blanda språk
Som standardinställning använder cellerna anteckningsbokens standardsspråk. Du kan åsidosätta standardspråket i en cell genom att klicka på språkknappen och välja ett språk i den nedrullningsbara menyn.

Du kan också använda det magiska språkkommandot %<language> i början av en cell. De magiska kommandon som stöds är: %python, %r, %scalaoch %sql.
Anteckning
När du anropar ett språkmagiskt kommando skickas kommandot till REPL i körningskontexten för anteckningsboken. Variabler som definierats på ett språk (och därmed i REPL för det språket) är inte tillgängliga i REPL för ett annat språk. REPL:er kan endast dela tillstånd via externa resurser, till exempel filer i DBFS eller objekt i objektlagring.
Anteckningsfiler stöder också några få hjälpmagiska kommandon.
-
%sh: Gör att du kan köra shell-kod i notebook-filen. Om du vill misslyckas med cellen om shell-kommandot har en slutstatus som inte är noll lägger du till alternativet-e. Det här kommandot körs bara på Apache Spark-drivrutinen och inte på arbetarna. Om du vill köra ett gränssnittskommando på alla noder använder du ett init-skript. -
%fs: Gör att du kan användadbutilsfilsystemkommandon. Om du till exempel vill köra kommandotdbutils.fs.lsför att visa filer kan du ange%fs lsi stället. Mer information finns i Work with files on Azure Databricks. -
%md: Gör att du kan inkludera olika typer av dokumentation, inklusive text, bilder och matematiska formler och ekvationer. Se nästa avsnitt.
Markering och automatisk komplettering av SQL-syntax i Python kommandon
Syntaxmarkering och SQL autocomplete är tillgängliga när du använder SQL i ett Python kommando, till exempel i ett spark.sql kommando.
Utforska SQL-cellresultat
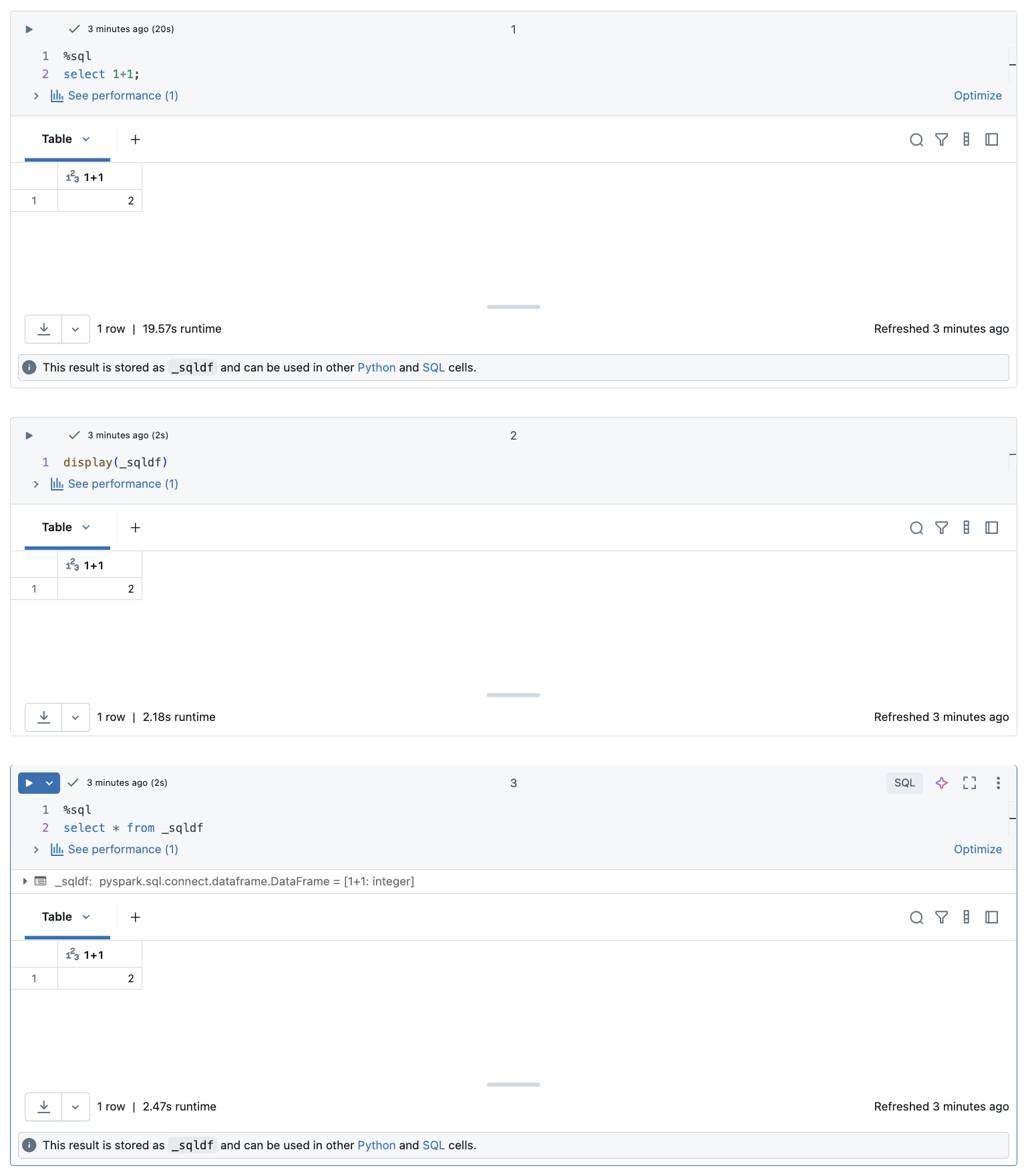
I en Databricks-notebook-fil görs resultat från en SQL-språkcell automatiskt tillgängliga som en implicit DataFrame tilldelad till variabeln _sqldf. Du kan sedan använda den här variabeln i alla Python- och SQL-celler som du kör efteråt, oavsett deras position i notebook-filen.
Anteckning
Den här funktionen har följande begränsningar:
- Variabeln
_sqldfär inte tillgänglig i notebook-filer som använder ett SQL-lager för beräkning. - Användning av
_sqldfi efterföljande Python celler stöds i Databricks Runtime 13.3 och senare. - Användning
_sqldfi efterföljande SQL-celler stöds endast på Databricks Runtime 14.3 och senare. - Om frågan använder nyckelorden
CACHE TABLEellerUNCACHE TABLEär variabeln_sqldfinte tillgänglig.
Skärmbilden nedan visar hur _sqldf kan användas i efterföljande Python- och SQL-celler:
Viktigt!
Variabeln _sqldf omtilldelas varje gång en SQL-cell körs. Om du vill undvika att förlora referensen till ett specifikt DataFrame-resultat tilldelar du det till ett nytt variabelnamn innan du kör nästa SQL-cell:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Köra SQL-celler parallellt
När ett kommando körs och anteckningsboken är kopplad till ett interaktivt kluster kan du köra en SQL-cell samtidigt med det aktuella kommandot. SQL-cellen körs i en ny, parallell session.
För att köra en cell parallellt:
Klicka på Kör nu. Cellen körs omedelbart.

Eftersom cellen körs i en ny session stöds inte tillfälliga vyer, UDF:er och implicit Python DataFrame (_sqldf) för celler som körs parallellt. Dessutom används standardkatalog- och databasnamnen under parallell körning. Om koden refererar till en tabell i en annan katalog eller databas måste du ange tabellnamnet med hjälp av namnområdet på tre nivåer (catalog.schema.table).
Köra SQL-celler i ett SQL-lager
Du kan köra SQL-kommandon i en Databricks-notebook-fil på ett SQL-lager, en typ av beräkning som är optimerad för SQL-analys. Se även Använda en notebook-fil med ett SQL-lager.
Använda magiska kommandon
Databricks-notebook-filer stöder olika magiska kommandon som utökar funktioner utöver standardsyntaxen för att förenkla vanliga uppgifter. Linje-magierna är försedda med prefixet % och tillämpas på en enda rad. Cellmagi har prefixet %% och gäller för hela cellen.
| Magiskt kommando | Exempel | Beskrivning |
|---|---|---|
%python |
%pythonprint("Hello") |
Växla cellspråk till Python. Körs Python-kod i cellen. |
%r |
%rprint("Hello") |
Växla cellspråk till R. Kör R-kod i cellen. |
%scala |
%scalaprintln("Hello") |
Växla cellspråk till Scala. Kör Scala-kod i cellen. |
%sql |
%sqlSELECT * FROM table |
Växla cellspråk till SQL. Resultaten är tillgängliga som _sqldf i Python/SQL-celler. |
%md |
%md# TitleContent here |
Växla cellspråk till Markdown. Renderar Markdown-innehåll i cellen. Stöder text, bilder, formler och LaTeX. |
%pip |
%pip install pandas |
Installera Python-paket (anteckningsboksspecifikt). Se Notebook-specifika Python-bibliotek. |
%run |
%run /path/to/notebook |
Kör en annan notebook-fil och importera dess funktioner och variabler. Se Notebook-arbetsflöden. |
%fs |
%fs ls /path |
Kör dbutils-filsystemkommandon. Förkortning för dbutils.fs kommandon. Se Arbeta med filer. |
%sh |
%sh ls -la |
Kör gränssnittskommandon. Körs endast på drivrutinsnoden. Använd -e för att avbryta vid fel. |
%tensorboard |
%tensorboard --logdir /logs |
Visa TensorBoard-användargränssnittet direkt. Endast tillgängligt på Databricks Runtime ML. Se TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Ange maximal storlek för cellutmatning. Intervall: 1–20 MB. Gäller för alla efterföljande celler i Notebook. |
%skip |
%skipprint("This won't run") |
Hoppa över cellkörning. Förhindrar att cellen körs när anteckningsfilen körs. |
%%profile |
%%profilemy_function() |
Profilering av Python-kodkörning. Visar ett hierarkiskt anropsträd med tidsinformation. Kräver Databricks Runtime 17.2 och senare. |
%%oprofile |
%%oprofilemy_function() |
Skapande av profilobjekt under cellens körning. Visar en tabell med nya nettoobjekt som skapats, grupperade efter typ. Kräver Databricks Runtime 17.2 och senare. |
Anteckning
IPython Automagic: Notebooks i Databricks har IPython automagic aktiverat som default, vilket gör att vissa sådana kommandon kan fungera pip utan IPython-prefixet %. Fungerar till exempel pip install pandas på samma sätt som %pip install pandas.
Viktigt!
- Variabler och tillstånd är isolerade mellan olika språk-REPL:er. Till exempel är Python variabler inte tillgängliga i Scala-celler.
- En notebook-cell kan bara ha ett cellmagikommando, och det måste vara den första raden i cellen.
-
%runmåste vara i en cell av sig själv, eftersom den kör hela anteckningsboken in-line. - När du använder
%pippå Databricks Runtime 12.2 LTS eller tidigare placerar du alla paketinstallationskommandon i början av din notebook eftersom Python-tillståndet återställs efter installationen.